From rigid ETL jobs to intelligent, self-healing data systems
Introduction — A Personal Note
When I started working with data engineering systems nearly two decades ago, pipelines were very different from what we imagine today.
We used tools like:
- Informatica
- DataStage
- SQL Server Integration Services (SSIS)
- Custom Python scripts
Everything was predefined, scheduled, and fragile.
If something failed at 2 AM, we waited until morning logs.
If a schema changed, we fixed pipelines manually.
If data broke, dashboards went dark.
That was normal.
But today, something fundamental is changing.
We are no longer just building pipelines.
We are building systems that can think, decide, and act.
That shift is called:
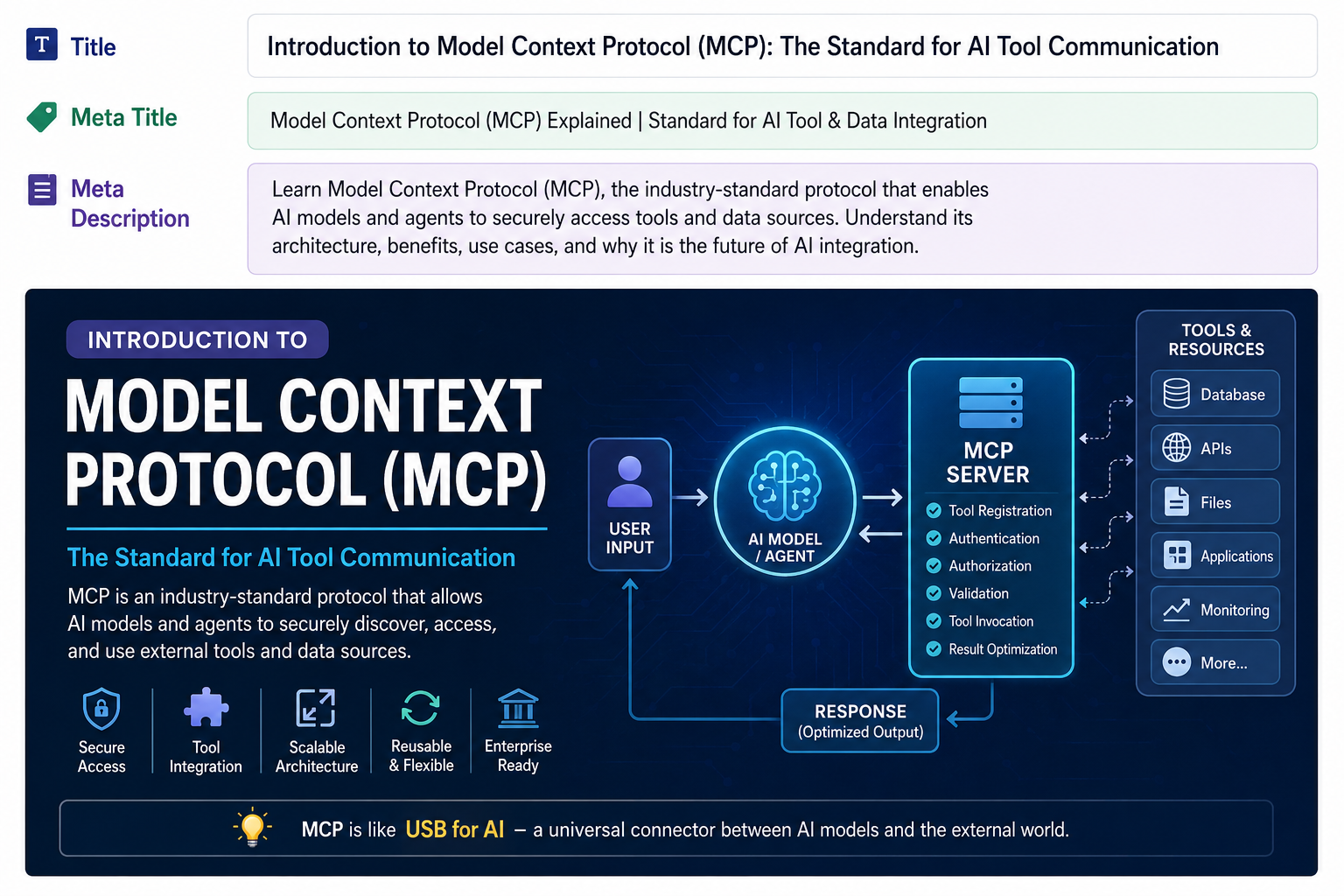
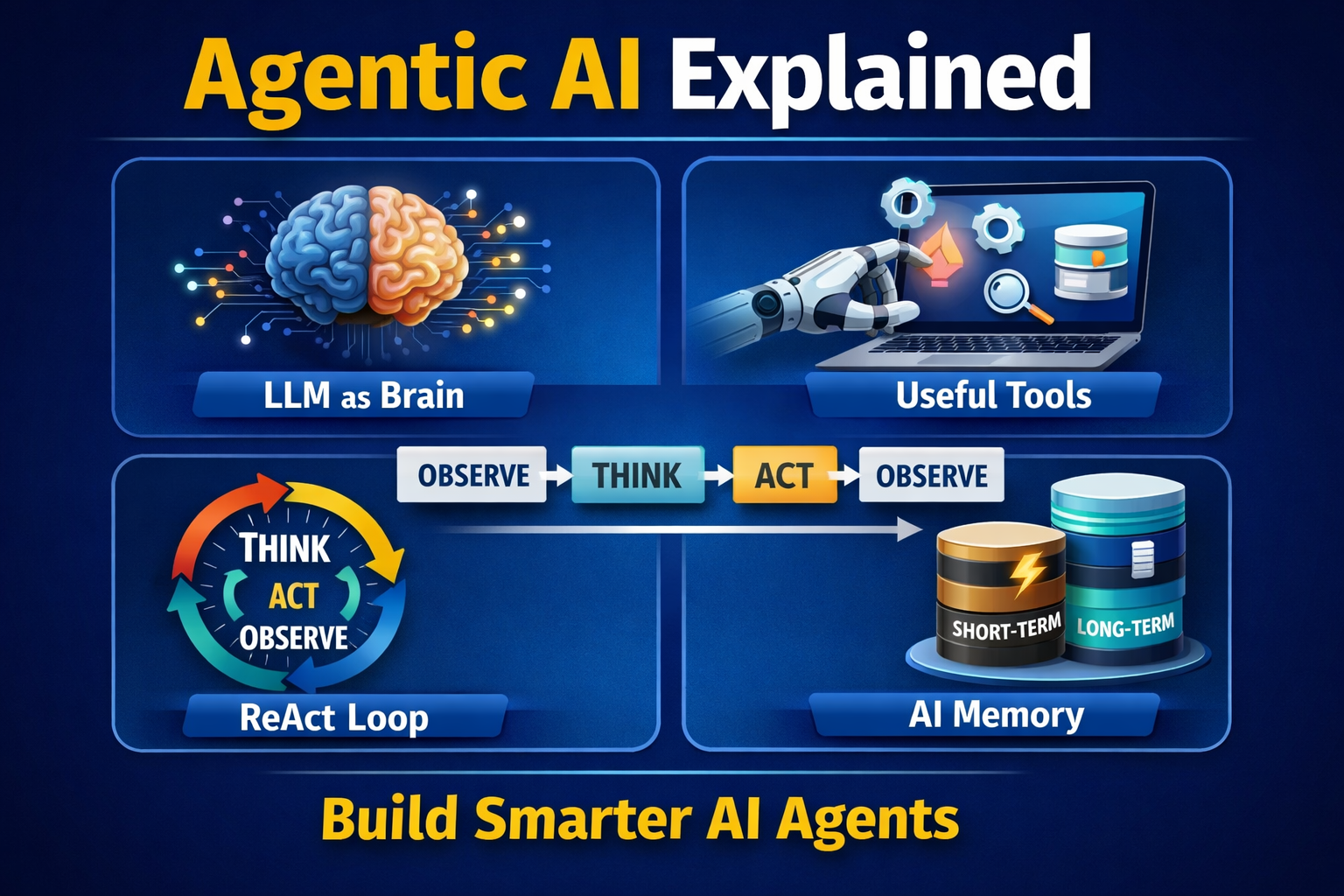
Agentic AI in Data EngineeringWhat is Agentic AI in Data Engineering?
Agentic AI refers to systems where LLM-powered agents can plan, reason, and execute tasks using tools and memory.
In data engineering, this means pipelines are no longer static workflows.
Instead, they become adaptive systems that can:
- Understand data requests in natural language
- Decide which transformation is required
- Execute SQL, Spark, or Python dynamically
- Detect errors and self-correct
- Learn from past executions
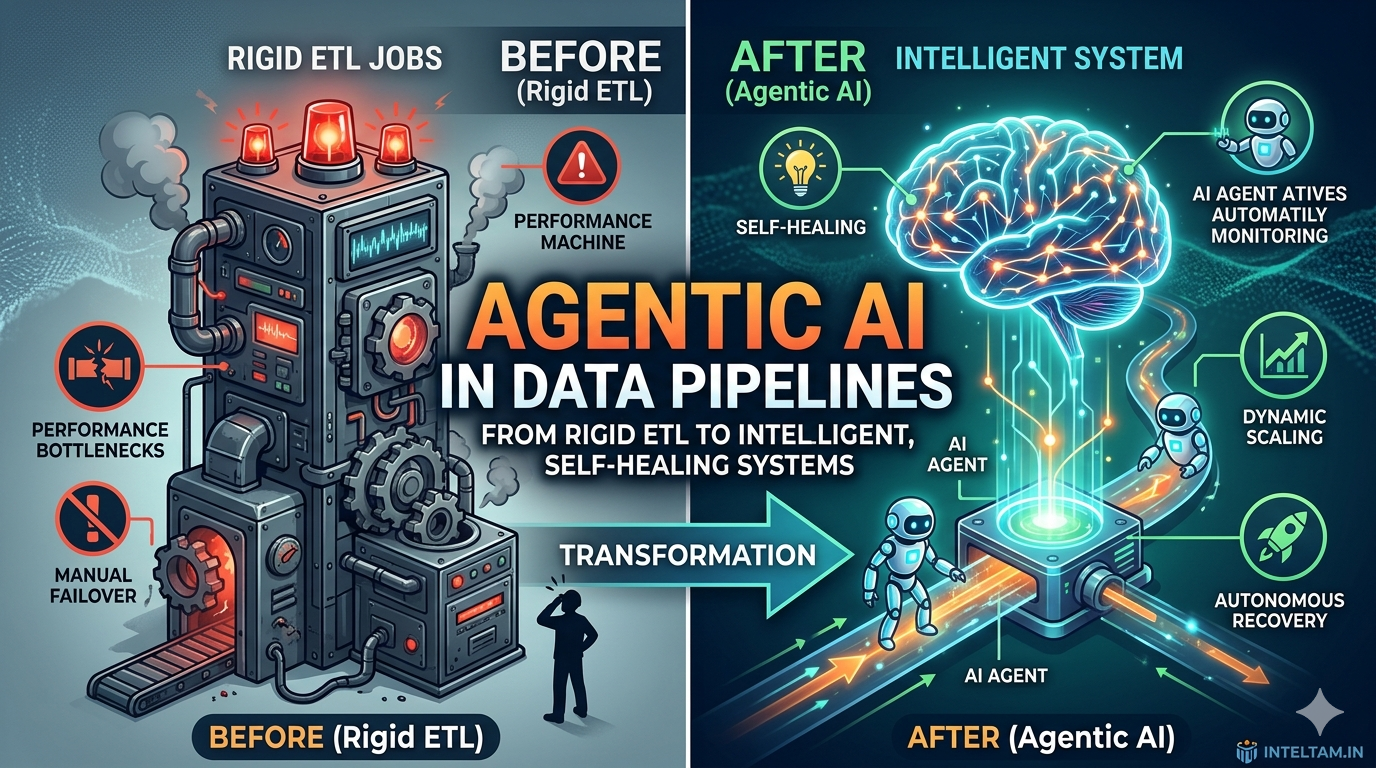
Traditional vs Agentic Data Pipeline
Let’s understand the shift visually.
Diagram 1: Pipeline Evolution
TRADITIONAL DATA PIPELINE
-------------------------
Source Data
↓
ETL Job (Fixed Logic)
↓
Data Warehouse
↓
Dashboard / Reports
❌ If failure → Human intervention needed
❌ No adaptability
❌ Static logic
----------------------------------------------------
AGENTIC AI PIPELINE
-------------------
User Request / System Event
↓
AI Agent (Planner)
↓
Tool Selection Layer
(SQL / Spark / API / Python)
↓
Execution Engine
↓
Validation Agent
↓
Memory + Learning Store
↓
Output / Insight / Action
✔ Self-healing
✔ Adaptive execution
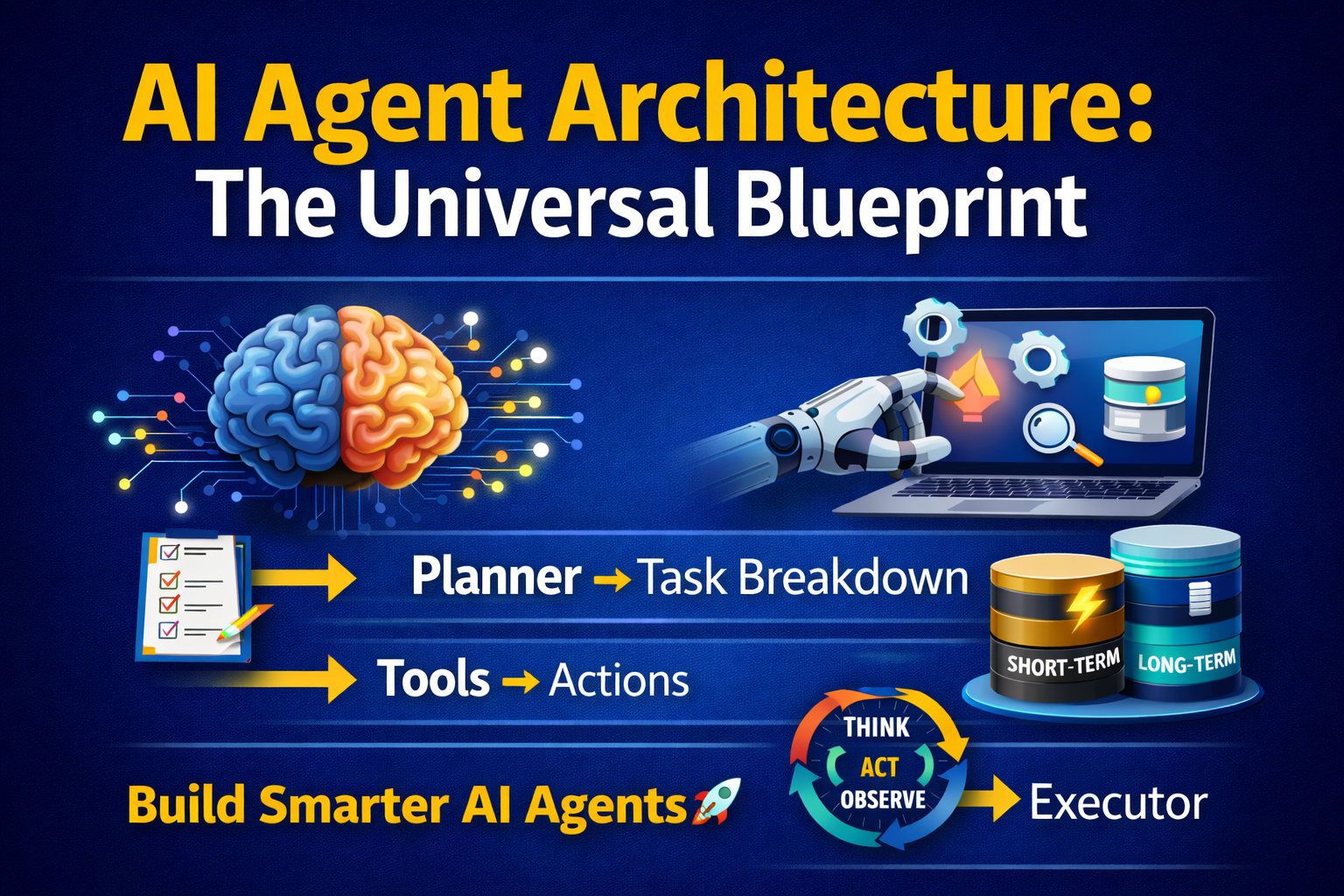
✔ Intelligent decision makingHow an Agentic Data Pipeline Works
Let’s break it down step-by-step in a practical way.
Step 1: Request Understanding
A user asks:
“Show me monthly revenue by region for the last 6 months”The agent understands:
- Data source needed
- Time range
- Aggregation logic
Step 2: Planning Agent
The system creates a plan:
- Fetch sales data
- Filter last 6 months
- Group by region
- Aggregate revenue
Step 3: Tool Execution
Now the agent chooses tools:
- SQL engine for querying
- Python for transformation
- Spark for large-scale processing
Step 4: Validation Layer
Before returning results:
- Schema check
- Null validation
- Outlier detection
Step 5: Memory + Learning
System stores:
- Query patterns
- Failures and fixes
- Performance optimizations
Next time → faster + smarter execution
Diagram 2: Agentic Data Engineering Architecture
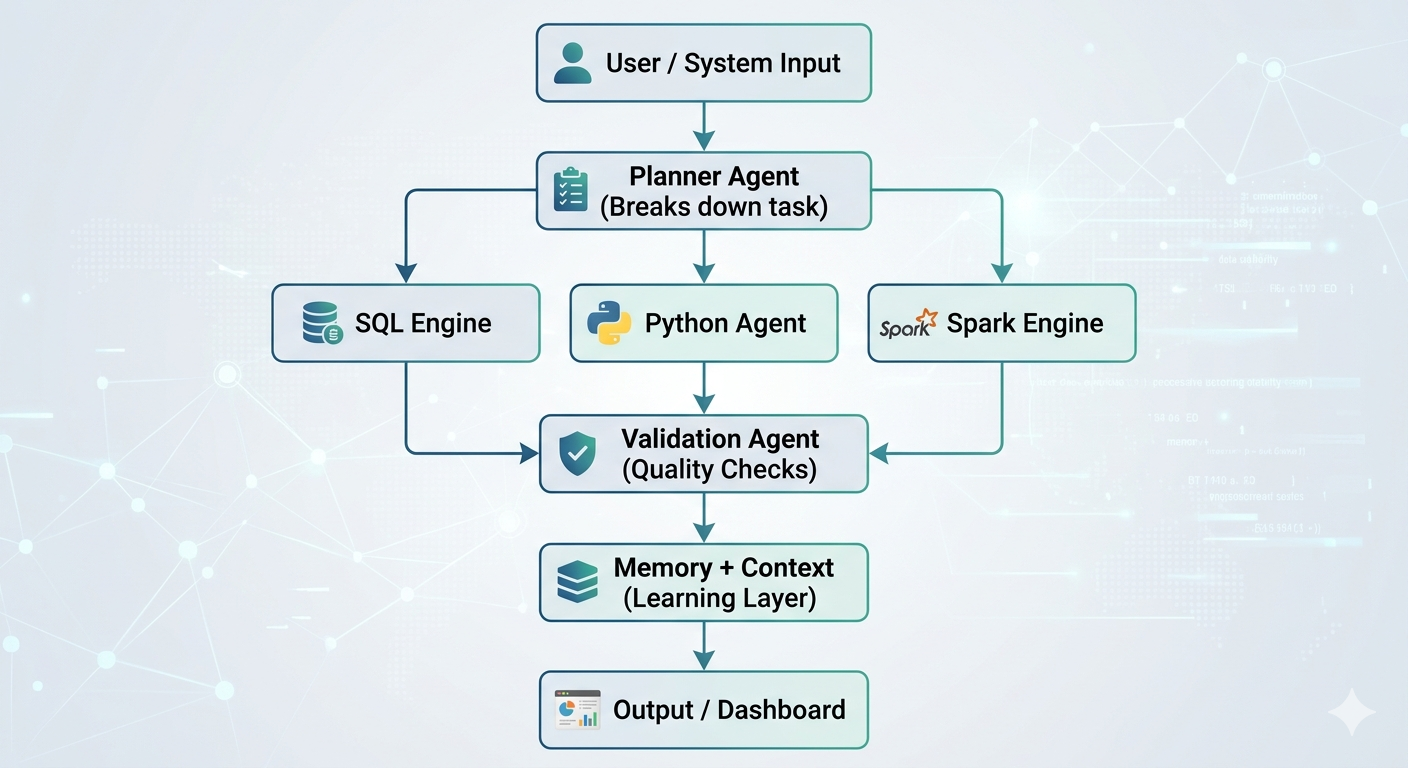
Real-World Use Cases
Now let’s connect theory to reality.
1. Self-Healing ETL Pipelines
If a SQL query fails due to schema change:
Old world:
❌ Pipeline breaks → engineer fixes manually
Agentic world:
✔ Agent detects failure
✔ Rewrites query
✔ Retries execution
✔ Logs fix for future use
2. Natural Language Data Queries
Instead of writing SQL:
“Show top 10 customers by revenue”
Agent automatically:
- Converts to SQL
- Executes query
- Returns structured output
This reduces dependency on manual query writing
3. Automated Data Quality Monitoring
Agents continuously monitor:
- Null spikes
- Duplicate records
- Schema mismatches
- Data drift
And can:
- Alert engineers
- Auto-clean data
- Trigger fallback pipelines
4. Intelligent Pipeline Orchestration
Instead of fixed DAGs:
- Agent decides execution path dynamically
- Chooses cost-efficient compute
- Adjusts based on data volume
5. AI Debugging Assistant for Data Pipelines
When pipeline fails:
Agent:
- Reads logs
- Identifies root cause
- Suggests fix
- Or directly applies patch
This alone can save hours of debugging.
Why This Shift Matters
This is not just automation.
This is decision-making moving into the system itself.
We are moving from:
“Humans define every step”
to
“Humans define goals, AI defines execution”
From My Perspective (18+ Years in Data Engineering)
One thing is very clear from my experience:
Most data engineering effort is not building pipelines —
it is maintaining them.
Fixing failures
Handling schema changes
Debugging overnight issues
Managing dependencies
Agentic AI does not remove engineers.
It removes the repetitive burden.
And allows engineers to focus on:
- Architecture
- Optimization
- System design
- Business impact
The Future of Data Engineering
In the next few years:
- SQL writing will reduce significantly
- ETL pipelines will become self-healing
- Data engineers will become AI system designers
- Natural language will become the primary interface
- Agents will manage end-to-end workflows
Final Thoughts
Agentic AI is not just a tool upgrade.
It is a paradigm shift in how we build data systems.
We are moving from:
📊 Static pipelines
→
🤖 Intelligent autonomous systems
And this transition has already started.
The question is not if it will happen.
The question is:
How ready are we to design systems that think?