Introduction
Large Language Models (LLMs) are becoming the backbone of modern AI systems. Organizations increasingly rely on services from companies like OpenAI, Google, and Anthropic to power chatbots, copilots, and intelligent applications.
However, one important question often arises in enterprise environments:
How do we verify the tokens consumed by LLM APIs and ensure accurate billing?
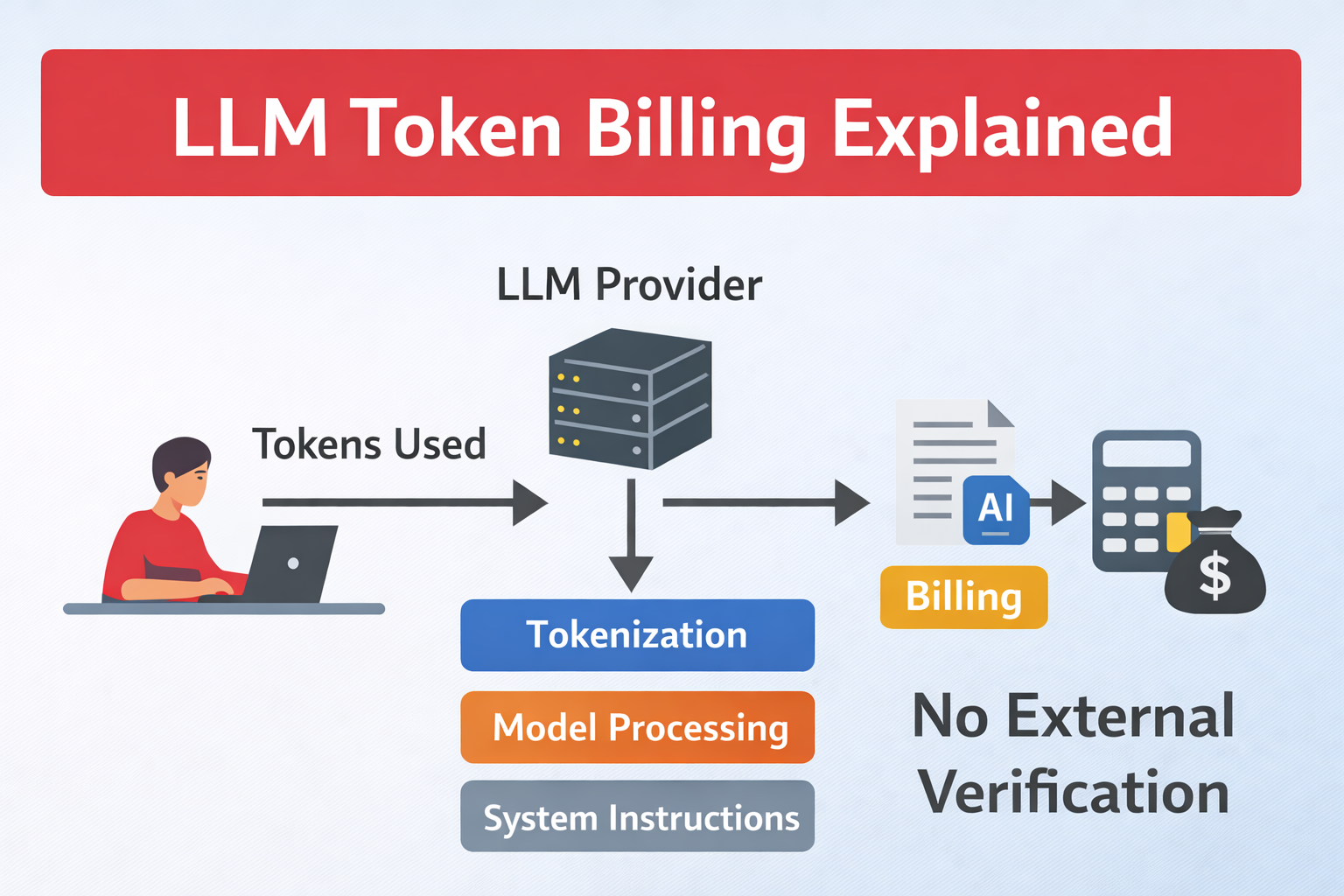
Unlike traditional cloud computing metrics such as CPU usage or storage consumption, LLM token billing lacks independent third-party verification.
Understanding Token-Based Billing
Most LLM providers charge based on tokens.
A token is a small piece of text. It may be:
- a word
- part of a word
- punctuation
- whitespace
Example text:
Artificial Intelligence is powerfulPossible tokens:
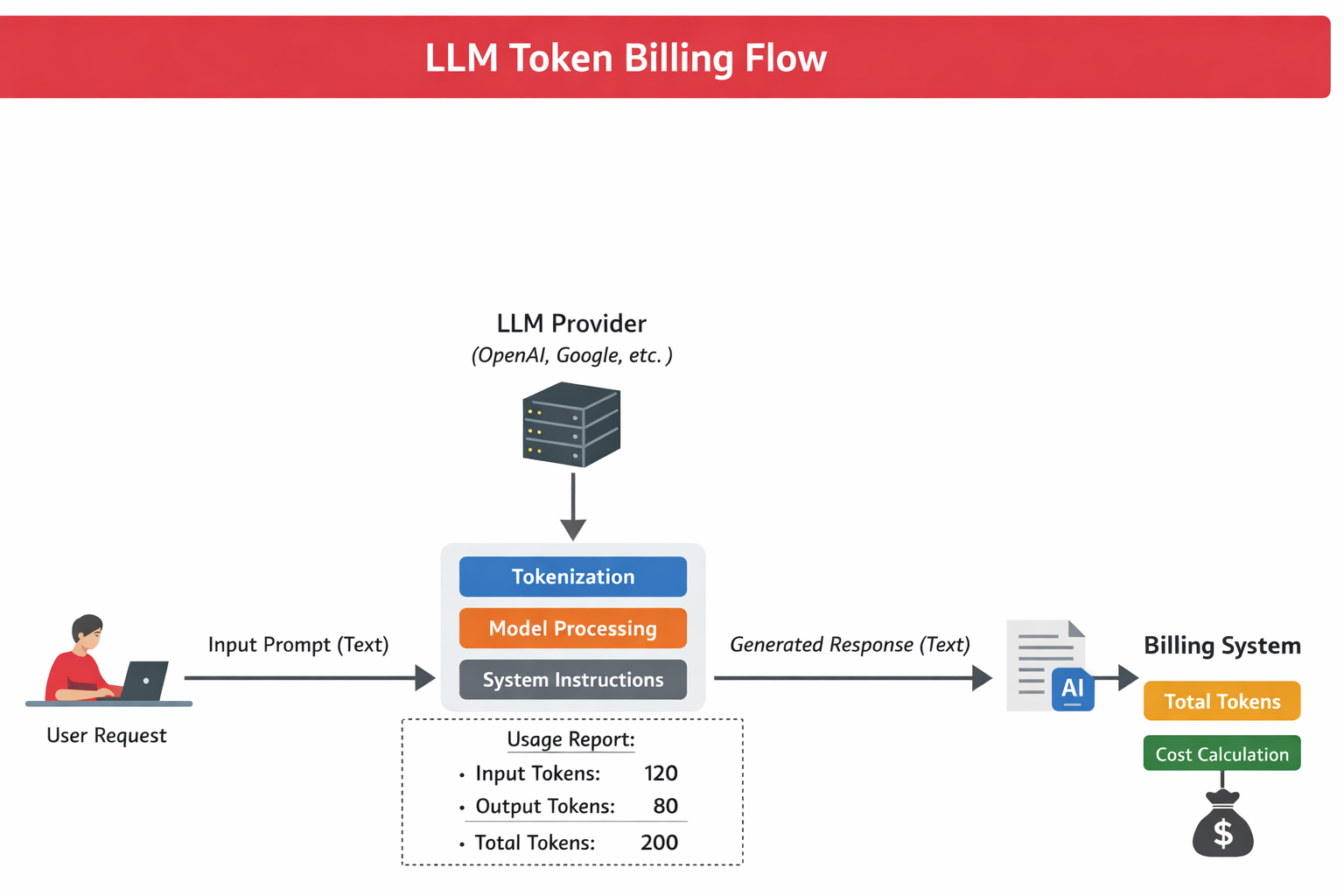
["Artificial", " Intelligence", " is", " powerful"]The total tokens = input tokens + output tokens.
If a prompt contains 120 tokens and the model generates 80 tokens, billing is based on 200 tokens.
LLM Token Billing Flow – How prompts, tokenization, and responses contribute to API billing:
How Tokens Are Counted
Token counting depends on the tokenizer used by the model.
For example, tiktoken is used for many OpenAI models.
Example Python code:
import tiktoken
enc = tiktoken.encoding_for_model("gpt-4")
tokens = enc.encode("Hello, how are you?")
print(len(tokens))This helps estimate token usage before sending a request.
However, this is only an approximation.
The Transparency Problem
The real challenge is that token counting happens inside the provider's infrastructure.
When an API response is returned, the provider reports usage:
usage:
prompt_tokens: 120
completion_tokens: 80
total_tokens: 200But this value is generated internally by the provider.
There is currently no universal mechanism for independent verification.
Why Third-Party Verification Is Difficult
Several factors make independent verification challenging:
1. Proprietary Tokenizers
Each model may use a different tokenizer algorithm.
2. Hidden System Prompts
Providers often include internal prompts that developers cannot see.
3. Model Processing Steps
Some providers may add internal tokens for:
- safety instructions
- system prompts
- context formatting
These tokens may affect billing.
Enterprise Impact
For small projects the difference may be negligible. But for large AI systems the impact can be significant.
Example scenario:
| Requests per day | Tokens per request | Monthly tokens |
|---|---|---|
| 100,000 | 2,000 | 6 billion tokens |
Even small inaccuracies could affect cost monitoring and budgeting.
How Companies Monitor LLM Usage
To manage this risk, engineering teams use observability tools like:
- Langfuse
- Helicone
- Arize AI
These tools track:
- prompts
- responses
- estimated tokens
- approximate cost
However, they still rely on provider tokenization logic.
Best Practices for Engineering Teams
To control LLM costs, many teams implement the following strategies:
Prompt optimization
Shorter prompts reduce token consumption.
Context compression
Retrieve only relevant information instead of sending full documents.
Response limits
Set a maximum output token limit.
Usage logging
Track every API request and estimated token usage.
The Future of AI Billing Transparency
As AI adoption grows, demand for transparent AI billing standards will increase.
Possible future solutions include:
- standardized tokenization protocols
- verifiable AI usage logs
- independent auditing tools for AI APIs
Until such standards emerge, organizations must rely on internal monitoring and estimation methods.
Conclusion
Token-based billing is central to how modern AI APIs are priced. Yet the lack of independent verification mechanisms creates a transparency challenge for organizations deploying AI at scale.
Understanding how tokenization works and implementing monitoring strategies can help engineering teams manage costs effectively.
As the AI ecosystem matures, greater transparency in LLM billing will likely become an industry requirement.
